Our Blog
Working with bit fields – optimize your code
Bitwise logical operations and packing data into bitfields is a very elementary programming technique - in fact, every microprocessor uses it internally to achieve "higher" goals like addition, subtraction, multiplication, division, and more. Nevertheless, many people who write amazing software in "high" languages are not really comfortable when it comes to bit manipulations, even if these can, as we have often seen in the Nextion Sunday Blog's demo projects, make your code more compact, using less memory and running quicker. Since I get more and more reader's feedback in that sense, I decided to make a compact writeup, giving you the required knowledge at hands, not only to decipher but also to create amazing things.
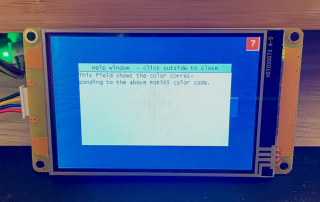
Universal UI on-screen help framework for Nextion HMI
In the Nextion user forums, a participant from Europe, let's call him M., asked an interesting question. What he wants to achieve is activating a "Help" mode on his Nextion project. That means that after activating this help mode, the user would click on an arbitrary component and instead of executing the component's event code, a help screen with explanations would be displayed. Since in his project, there are nearly 1000 components on several screens, reworking each single component's event code to decide if the event code should be executed or the help screen displayed, is definitively not an option. So, he thought that he'd use a TouchCap component to intercept the event chain before the component's own event code was executed, to decide if, in case the help mode was active, the help screen would be displayed. But his problem was that the component's own TouchPress and/or TouchRelease event code would still be executed afterwards, probably going to a different page, which would prevent displaying the help text correctly...
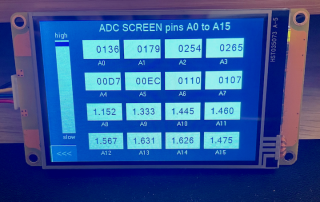
The Nextion Mega I/O Project – Part 5
The Nextion Mega I/O Project - Part 5 Please read before: The Nextion MEGA IO project -

The 2024 Editorial
First of all, a Happy New Year 2024 to you, dear readers, from my Nextion colleagues in Shenzhen/China, in Canada, and from myself in France! After a quick look over the past 4 years, let's draw the roadmap for the coming year together!

The Universal Nextion Xmas Screen Saver
What about a nice Screen saver for your Nextion HMI project? When I tell you now that it adapts automatically to your screen resolution and orientation, and work with all Nextion series, so that it will really fit into every project? Wouldn't that be a nice gift for these holidays?
NEXTION and SONOFF Christmas Sales + huge speedup of the Nextion MEGA IO project
NEXTION and SONOFF Christmas Sales Christmas approaches and I think that the following offers for NEXTION and