Strings & arrays – continued
A quick look back and a question
A few weeks ago, I wrote this article about using a text variable as an array, either an array of strings or an array of numbers, using the covx conversion function in addition for the latter, to extract single elements with the help of the spstr function. It’s a convenient and almost a “one fits all” solution for most use cases and many of the demo projects or the sample code attached to the Nextion Sunday Blog articles made use of it, sometimes even without mentioning it explicitly since it’s almost self-explaining.
Then, I got a message from a reader, writing: “… Why then didn’t you use it for the combined sine / cosine lookup table in the flicker free turbo gauge project?”
The answer and deeper insight
The aforementioned convenience has its price. To understand this, we have to think the same way as the integrated MCU of our Nextion HMI does. Although internals of the firmware are closed source, we may admit that the implementation of the spstr function in the Nextion firmware is close to similar implementations in other languages. Let’s thus look to one of these pseudo array strings. The array elements are all concatenated with a separator character s in-between. Typically, one uses a character which doesn’t appear in the text or numeric elements, like the semicolon ; or the vertical bar | while others like the comma , can lead to problems in these European countries where it’s used as a decimal separator. Thus, better don’t use commas. Our example string might look like that:
element0;element1;element2;element3;element4;
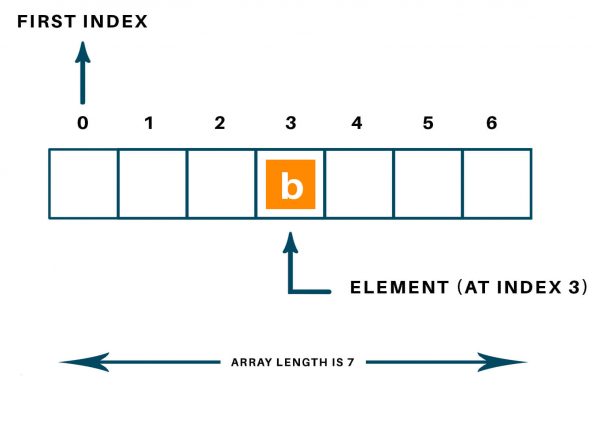
which is the known CSV format. Now, if we want the spstr function to retrieve the element with the index 3, what does the internal MCU of the Nextion do? It will loop through each character of the string and compare it to the separator character. To find the beginning of the nth (in our example 3rd) element, it must locate the nth appearance of the separator and remind its position p in a variable (let’s call it b like “beginning”), then move on until the (n+1)th appearance of the separator, and save it in a variable (e like “end”). Then, it has to copy all characters from position b + 1 to e – 1 into the target variable since we don’t want to have the separators included.
Until it knows the value of b, 27 loop runs with compares have to be executed in our example to retrieve the element with index 3, and even 36 until e will be known. Thus, the price we pay is lower speed. The higher the array index to retrieve, the more time is required by spstr to locate and retrieve the element. What we get in exchange is the convenience that our pseudo array may contain elements of arbitrary length and we’ll get always a correct result.
Ok, searching for the separators is time and memory consuming, are there alternatives ?
Yes, there are. The magic keyword is “fixed length”. When each array element has the same length l, we do not need separators (which can save memory), and we can directly calculate the starting position p of the nth element which is p = n * l. Thus, to copy the element, we simply copy the l characters, starting at p = n * l. And that’s it. No loops, no compares, which speeds things up considerably.
That’s what I did in the Turbo gauge project where I needed a trigonometric lookup table with 30 elements, each being a 2 digit number which makes only 60 characters. Using separators, the same table would have a length of 86 characters, 57 for the 30 elements, and 29 separators in-between like 0;4;7;…;69;70;70. When looking at our 60 character pseudo array string in the HMI file
000407111518222528323538414447495254575961626465676868697070
we can see that there is still a very little “waste of memory” – The first three elements, 0, 4, and 7 had to be left padded with zeros to fit into the scheme. But that’s nothing compared to the 29 omitted separators. And the access to a specific element is much quicker!
And what if I tell you, that there is still some potential for optimization?
Choosing the best number format
In the above example, we had a number range from 0 to 70 because the gauge needle’s length was fixed to this value. But if we wanted to explore the full 8bit range from 0 to 255, we’d go with 3 digit numbers, using 3 characters (aka bytes) for a single byte? No. We’d use the hexadecimal format where, instead of 0 to 255, we can get away with 00 to FF, which takes only 2 characters per byte. 33% memory saved.
Outlook
In my next article, we’ll see several new things: We’ll get another practical example using a fixed length lookup table, but this time, we’ll have the Nextion calculate and populate it itself to generate a beautiful curve. And we will have the Nextion draw this curve, not pixel by pixel like the waveform component does, but curve segment by curve segment which is more esthetic. Thus, be prepared to meet another custom or self built component!
Thank you for reading!
Happy Nextioning!