The Sunday Blog: Characters and their ASCII codes
A bit of history, first
Most developers know that a character like “A” is represented inside microprocessor systems as a simple number. That’s called encoding. Everything started with teletype machines which used a 5bit encoding. The so-called Baudot-code, named after Mr Émile Baudot who invented it in 1874) allowed to encode the 26 uppercase chars of the latin alphabet, the ten numbers from 0 to 9, some interpunction and and some non-printable control characters within that limited 32 character space, using a sophisticated shifting system, comparable to our modern caps lock function.
Later, when the first computers came up, with screens and printers, the Baudot code was extended from 5 to 7 bits, giving a 128 character space. Now, almost everything could be encoded without shifting and tricks (they thought): Upper and lowercase letters, numbers, special characters, interpunction, mathematical signs and more control characters. Again, everybody was amazed, until people hit the flaws of the ASCII system when they wanted to do text I/O in other languages than English. That gave birth to the 8bit code page system: In whatever code page, the first half, the characters #0 to #127 remained the same, identical to the ASCII code. In the upper half, the characters #128 to #255 were used for encoding national specifics, like for example à, é, ô, or ç in France, ä, ö, ü, ß in Germany, and so on.
In order to display or to print a text correctly, you’d have to know which code page was used for encoding, so that you could use the same for decoding. The ISO standard superseded and re-ordered these code pages with the intention to reduce the national chaos, but without success. And we didn’t yet talk about all the languages which use non-latin characters, mostly in Asia. The UTF standard was then created to encode everything, Latin, Cyrillic, Chinese, Japanese, Serbian, etc. plus interpunction, plus graphical block characters plus smileys, plus…, plus… A 32bit space is a great thing to encode more than 4 billions of symbols, but it’s not practical because each symbol would eat up 4 precious bytes. Thus, the UTF system applies a few tricks: First of all, the numbers #0 to #127 represent still – you guess it – the ASCII character set, which is still the biggest common denominator of character encoding. Then, parts of the upper half of the first byte indicate if the current symbol is encoded in one, two, three or four bytes (step back to Baudot’s shifting system). And the encoding has been selected in a way that the more common a symbol is, the less bytes are required to encode it, which saves storage space and transmission bandwidth.
All that to tell you, that yes, even today in 2021, English is the predominant common language and the ASCII character set is still the gold and unambiguous standard for character encoding. That’s why in this article, we’ll look deeper into the relationship between a character and it’s numerical representation.
At machine and memory level: casting
A microprocessor gets a byte handed over for processing, for example 01000001b. It does not know if this byte is the number 65 or one of several bytes of a bigger number, or the letter “A”. At machine code and assembler level, it’s up to the developer and/or the compiler to make sure that this byte is interpreted and processed in the intended way.
Lower level programming languages like C allow thus to tell the compiler how it has to interpret and to handle a byte: We can declare byte x =65; and the compiler reserves a byte in memory and presets it with 01000001b. But if we want to use that byte later, we can cast (or reinterpret) by using it as (char) x which would make it usable as the letter “A”. The content of our memory cell is still unchanged, there is no conversion, it’s just the way in it is used which changes.
Finally and in reality, things are a little more complicated because the C compiler makes that character strings (not the Arduino String objects which are still a different beast) are terminated by a 0x00 byte to make a difference with fixed length numbers. You see, the struggle starts already! So, while casting might be the most efficient way, it takes a lot of care to interpret and to handle the same byte always accordingly, even in a long and complex program.
Higher programming languages
These have been invented to make the developer’s life easier. Often, variables can be initialized without even declaring their type. In PHP, for example, we can write $a=65; $b=”A”;. The PHP interpreter will guess that $a is numeric and $b a character. So far so good. But although both represent a numeric value of 65, writing $c = $a – $b would through a runtime error because you aren’t allowed to subtract a letter from a number, even if both are identical, and the result would be 0.
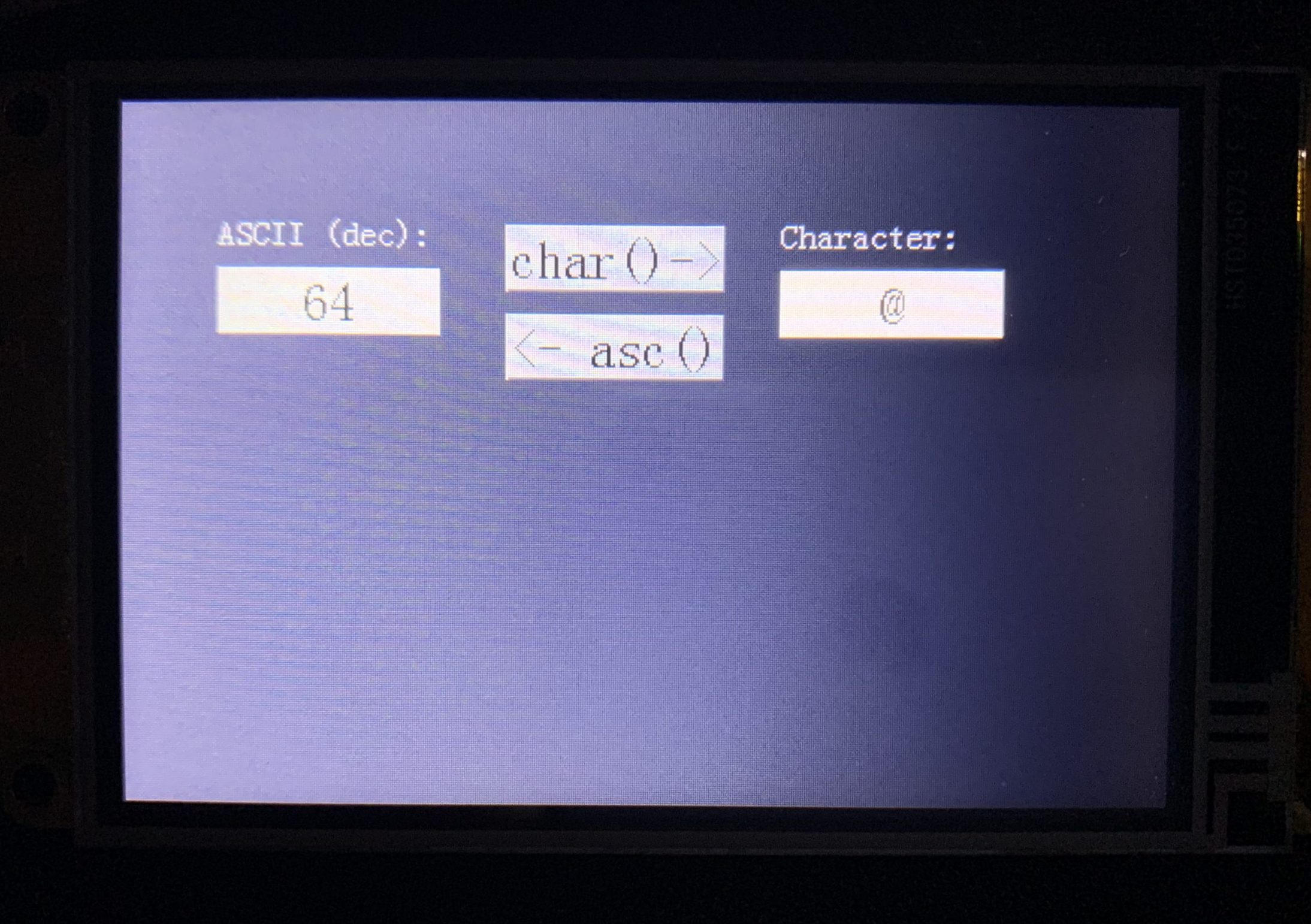
That’s why explicit conversion functions had been introduced in most programming languages. For example, char(65) would return “A” and asc(“A”) would return 65.
In the Nextion HMI world…
… casting isn’t the way to go, our programming language is basically too high and protects from confusion between numeric and text variables. Beyond that, conversion between characters and their numeric ASCII code is not a very common and often used task when designing smart GUIs. That’s why the Nextion firmware saves precious RAM and does not give us built-in conversion functions. But there is always the one or the other special use case, where it might be needed.
“If the system doesn’t give you a needed function, write it yourself!”. Thats what we do here. We’ll even be writing two functions, one to convert from the numeric ASCII code to a character, and one from a character to a numeric ASCII code. But first, we’ll consider a few things:
First, although the complete ASCII table contains 128 entries, 33 of them (#0 – #31 and #127) are non-printable characters. So, to save memory, our look-up table or array will only contain 95 entries and we’ll put a few fences around our functions to deal only with inputs from #32 to #126 for the char() function and to map these to an index from 0 to 94, and in the reverse case, in the asc() function, remap the 0 to 94 index to the ASCII codes #32 to #126.
Second, did we use the words “look-up table” and “array” above, although the Nextion Instruction set does not mention these? Yes, we did. Because we’ll be using the spstr (split string) command, which allows us to “pack” our array values into a long string and to split it at an arbitrary position by a separator character which we put in-between the array values. The separator must be a symbol which is NOT one of the ASCII codes from #32 to #126, and it must be a printable character to build our string. I decided for the British pound “£” character which has ASCII code #156. It’s just important that your HMI project uses an encoding like ISO-8859-1 which contains this symbol.
The look-up
… is thus a string variable, containing our 95 printable ASCII characters and 94 “£” separators in-between which gives it a total length of 189 characters. We put thus a text variable va0 with a txt_maxl attribute of 189 and a txt attribute containing
£!£"£#£$£%£&£'£(£)£*£+£,£-£.£/£0£1£2£3£4£5£6£7£8£9£:£;£<£=£>£?£@£A£B£C£D£E£F£G£H£I£J£K£L£M£
N£O£P£Q£R£S£T£U£V£W£X£Y£Z£[£\£]£^£_£`£a£b£c£d£e£f£g£h£i£j£k£l£m£n£o£p£q£r£s£t£u£v£w£x£y£z£{£
|£}£~Now, we have the space before the first £ separator, thus at index 0, the ! at index 1 and so on, until the tilde ~ at index 94.
The char() function
… is found in the touch press event code of the corresponding button. It checks first if the entry in the left (numeric with keypad) field n0 is between 32 and 126, and if yes, it subtracts 32 and executes the lookup in our table and writes the result in the right field. If the value is out of range, the field will be cleared:
// uses sys0 as scratch value if(n0.val>31&&n0.val<127) { sys0=n0.val-32 spstr va0.txt,t0.txt,"£",sys0 }else { t0.txt="" }
The asc() function
… is found in the touch press event of the second button. A scratch variable (sys0) will be incremented from 0 to 94 in a while() loop. A second scratch variable is preset to -1. Inside the while loop, the corresponding (to index sys0) character will be extracted to the va1 text variable and then be compared to the content of the right (text with keypad) field t0. If these are identical, sys1 will get the value from sys0 which is the result index. As soon as sys1 has a positive or zero value, the while() loop exits, because there is no need to look further when a match already occurred. The corresponding ASCII code is then calculated by adding 32 to sys1 before it is displayed in the left field. If no match occurred (should not happen, though), sys1 is always -1 after going through all indexes and would be displayed as a kind of error message.
// uses sys0,sys1 as scratch values sys0=0 sys1=-1 while(sys0<95&&sys1<0) { spstr va0.txt,va1.txt,"£",sys0 if(t0.txt==va1.txt) { sys1=sys0 //found!! } sys0++ } if(sys1>=0) { sys1+=32 } n0.val=sys1
That’s it! A few lines of code solve a “problem” which led to many discussion over many years in different Nextion user forums, the official one and some unofficial ones.
The demo project, containing all the code and constants can be downloaded here: char-asc.HMI
Feel free to re-use this in your own projects or to tinker around with it in the Nextion editor and simulator.
Happy Nextioning!